
How To Become Technical
A guide to building software products without an engineering background

Every couple weeks I have a friend tell me they want to become “technical”. Whether they’re trying to move into product management, or need to manage engineers for a side hustle, or simply want to work on a project with an engineer at their company. They don’t need to be as technical as engineers since they don’t want to be one full-time. Instead, they want to be technical enough to build software products that scale.
Many of them immediately ask for the best resources for learning to code. However, that’s not the place to start. Products aren’t successful because of the code, they’re successful because they profitably solve a user pain point. The greatest product builder of all time, Steve Jobs, didn’t know how to code.
The best way to become a technical partner to engineers is to master a few core principles for building successful products.
Instead of learning to code, build the skills to make sure the code is on track to solve an important problem in a sustainable way.
Here are a few principles that are universal to any successful software product:
Customer obsession - how does your product solve a real problem in a differentiated way?
Iterative product development - how do you build a version of the product that tests core hypotheses quickly and cheaply?
The role of key software components - what is the purpose of APIs, databases, the cloud, machine learning, etc. and how do they help build better products?
Understand the software development lifecycle - why do “simple” changes take so much time?
Interpreting data - how do you ask good questions?
Growth loops - how does a business make money and grow in a scalable way?
After working with product leaders from Instagram, Twitter, and Facebook, I’ve noticed that engineers didn’t always gravitate to the product managers with CS degrees or engineering backgrounds.
Instead, we wanted to work with people who applied foundational principles to build teams that consistently produced software that drove impact.
Customer Obsession
One of the most successful entrepreneurs of all time, Henry Ford, has famously said:
If I had asked people what they wanted, they would have said faster horses.
He’s 100% right. Customers are great at pointing out what is wrong with current solutions but aren’t great at identifying potential solutions. Therefore, use customer feedback as a way to gauge what problems are most acute. Then, figure out how to help solve this problem in a way that’s simpler and/or cheaper than current solutions.
Customers shouldn’t be your source of potential solutions because most customers, myself included, generally think in an incremental manner instead of exponential. For example, most solutions customers think of will be slight variations of existing solutions. Like a faster horse. However, as a technical product builder, your job is to understand the landscape of current and past solutions to build something that combines ideas in a novel way and is 10x better. One example is the iPhone.
While revealing the first version of the iPhone onstage at Macworld in 2007, Steve Jobs announced they would be releasing an iPod, a mobile phone, and breakthrough internet access technology. The crowd assumed it was three separate products:

It was the first iPhone.

Most people in the crowd expected it to look like this:

“An iPod that looks like a video game controller. Yayyy!!” *claps*
It probably would have looked similar to this if the team built it based on customer expectations. Instead, he understood exactly what the key issues were with current solutions.

“These look like calculators.”
And he had enough taste to know that a stylus isn’t great:

He goes on to say:
“Nobody wants a stylus. YUCK! We’re going to use the best pointing device in the world. We’re born with ten of them. We’re going to use a pointing device that we’re all born with. We’re going to use our fingers.

He knew the key pain points for consumers:
Buttons on a keyboard can’t change, so you’re limited to only a few symbols - the alphabet, numbers, punctuation. Sorry, no emoji’s.
A stylus was way too easy to lose.
So what did the team do? They focused on solving the pain point by creating something new that customers didn’t even know they wanted.
But how do you go from understanding customer pain points to building a product they love? That’s where iterative development comes in.
Iterative Product Development
One of the most controversial topics in tech is the idea of a “minimum viable product”, MVP for short. An MVP is a version of your product that you put in front of customers.
Arguments usually arise out of the debate of what “minimally viable” means. I think the illustration below is the best example of what a minimally viable product is and isn’t:
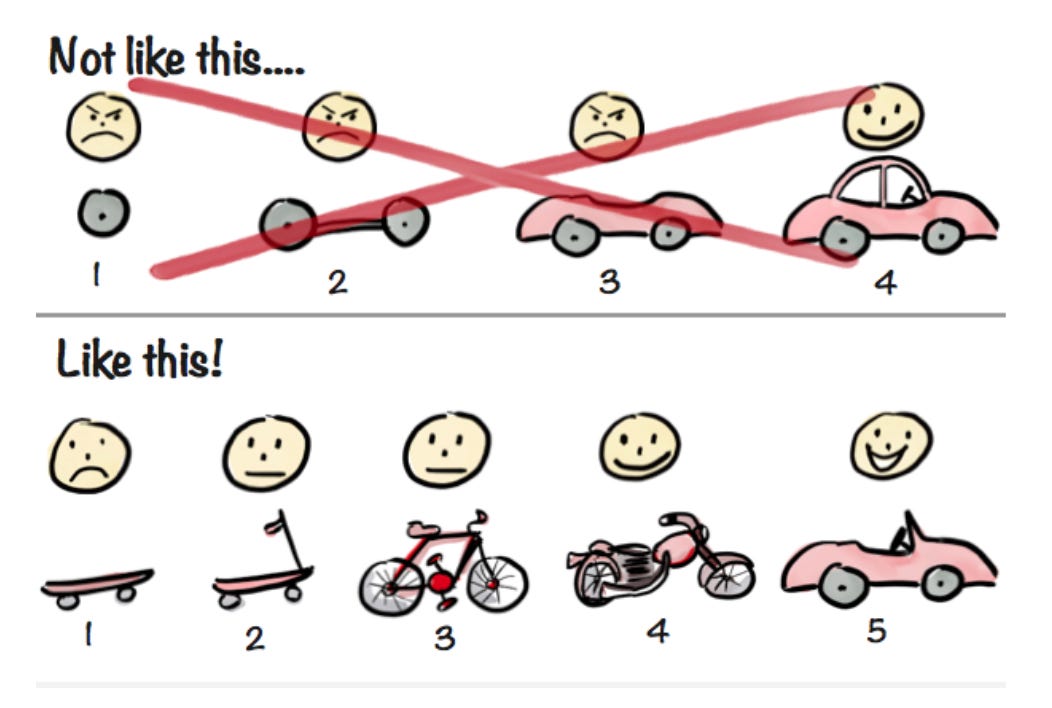
The “Not like this” example shows the cause of death for many startups. They run out of money before they even get to building the full product. Or a new technology renders your product obsolete. Or a competitor that beats you to market has already won the hearts and minds of customers.
The “Like this!” example is preferable because:
“Instead [of building the perfect product], we focus on the underlying need the customer wants fulfilled. Turns out that the underlying need is “I need to get from A to B faster”, and Car is just one possible solution to that.
Of course, the customer will probably still be unhappy with a skateboard when they want a car, but the skateboard still solves their problem better than their current solution (walking). A few key benefits of a tight feedback loop with customers include:
make better use of your cash flow or funding because your sole focus is building features that solve tangible customer needs
build a passionate user base that can form the foundation of your growth engine once the product matures
At my current company, Dharma, the core problem we’re solving is providing trust-minimized financial services. I.e., you don’t need to trust that the organization storing your funds won’t seize your assets because the logic behind where your money goes and how it’s stored is open to the public and network participants are economically incentivized to keep the network honest.
To validate that users wanted a product like this, the team started by identifying the biggest pain point: earning interest on cryptocurrency. As a result, the team built a high-yield crypto-backed savings account (currently over 7%).
However, the first version required users to have a Coinbase account and it took multiple days to transfer funds from Coinbase to Dharma. Yet, customers used this version of the product and told the team what their key pain points still were:
Sign up is slow
I want to deposit with a debit card
I want to withdraw to a bank account
No fees
Mobile app
The next iteration was removing the need to sign in with Coinbase which enabled users to begin depositing crypto in minutes.
After that, the team added the ability to deposit cash instantly with a debit card.
Then launched withdrawals to your bank account.
Then an iOS app.
All of this was done in about 2 and a half months.
By putting the product into users; hands, we know exactly what they want next:
lower fees on debit deposits
higher limits on debit deposits
Android app
Our singular focus right now is adding these features.
Another important idea of iterative product devleopment is the difference between reversible and irreversible decisions.
For example, if a bank shipped a bug that allowed hackers to steal funds, that would probably cause irreparable damage to their consumer brand. Alternatively, if a bank ships a bug that makes it harder for users to refer friends, they can quickly rollback the code and most users won’t ever hear about it.
As a result, think about what features are reversible and which aren’t and don’t compromise on the irreversible.
The Role of Key Software Components
This is the area that usually produces the most anxiety for “non-technical” people. There’s this myth that, in order to gain street cred from engineers, you need to understand how to design an infinitely scalable system that can ingest petabytes of data in minutes. Most engineers, including myself, don’t know how to do that!
Instead, understand the main tools that an engineer uses to create your product and be able to articulate the technical flow of some of the key features in your product (user onboarding, viewing posts, creating orders, etc.). This enables you to prioritize features and scope them on realistic timelines.
Understanding tools
The following tools are important to understand because you’ll probably hear engineers talking about them every day. You don’t need to be an expert. Reading the Wikipedia page, a few blog posts, and some YouTube videos should help you gain the understanding to have intelligent conversations with engineers. Here are a few basic definitions:
API (Application Programminig Interface) - A url that can be public or private which can return data (a list of users) or perform an action (post a tweet) based on the data you send it.
Database - Where application data is persisted so it isn’t lost.
Client - A computer executing code that reads data from a server and writes data to a server. Usually, it’s the device used by an end-user (smartphone, laptop, tablet, etc.)
Server - A computer running code that processes requests from a client device. There are specialized servers for databases, files, mail, apps, games, etc.
Cloud - Infrastructure managed by another company. this infrastructure can include components like databases, a notifications service, file storage, etc. Outsourcing your infrastructure to the cloud allows your team to focus on product features while cloud providers have some of the best engineers in the world building the electricity and plumbing of the internet. Providers source physical data centers, upgrade the code on machines, and build features on top of open source products. The big three providers are Amazon (AWS), Microsoft (Azure), and Google (GCP).
Programming Languages - Understand what different programming languages are good at. JavaScript is the most popular language because it can be used in a variety of domains (frontend, backend, mobile, etc.). Python is most popular amongst data scientists given its numerous statistics libraries. Ruby was popular a few years ago with startups looking to get started quickly. Most languages we use today were built since the 90’s. Cobol was invented in the 60’s and is still used by 92 of the top 100 banks today.
Web Frameworks - Frameworks provide reusable functionality which you can use to quickly build your app. On the frontend, React, built in Javascript, is the most popular framework. A couple popular backend frameworks include Django, which uses Python, and Ruby on Rails, which uses Ruby.
DevOps - Once your code for a new feature has been approved by another engineer, how does it go from your computer to running on your servers and user’s clients? This is where DevOps comes in. There are quite a few tools, like Docker, Kubernetes, and CircleCI, that automate a lot of this.
Algorithm - A series of steps that a computer follow (if x happens, do y)
Machine Learning - Statistical models and algorithms that automate decision making based on probabilities. Popular uses of machine learning today include image recognition (for self-driving cars to identify objects), speech-to-text (for voice technologies like Alexa), and recommendation systems (for your Instagram feed).
SQL (Structured Query Language) - a programming language that allows you to read and write data to your database.
Shouldn’t I learn how to code?
While I do think it’s very useful to build at least one full-stack web application (which includes a user interface connected to a backend API which reads / writes data to a database), you will be much more productive building products and working with engineers by focusing on key software components, and then learning to program enough to build a full-stack app.
Another useful exercise is to sit down with some engineers at your company and walk through the architecture and logic of some core features. Understanding these core flows will give you an appreciation for the complexity of the system which helps you decide which features to build.
For example, map out what happens after a user clicks “purchase” on your E-commerce app. An example answer could be:
The client (code on a mobile device) does some basic validation (e.g., there’s at least one item in the cart)
Then, the client formats the purchase data in a way that your API understands (e.g., a user ID, the ID’s of the items in the cart, the item total, tax amount, etc.)
Next, the client sends a request to your API by specifying the url / endpoint along with the data (e.g., https://api.amazon.com/orders/create)
The API then does some validation (e.g., use another API to make sure the user isn’t fraudulent, ensure the payment method is valid, etc.)
After validating the transaction, the API persists the data to a database so it can. be retrieved later, and may kick off some other code in the background like sending an email confirmation or sending the purchase event to a real-time analytics dashboard
Then, the API sends a response to the client, indicating that the transaction was successful and any additional data needed by the client (e.g., a finalized delivery estimate)
Lastly, since it’s a successful transaction, the client has some logic to redirect the user to a page outlining the transaction details
For bonus points, ask the engineer about different edge cases like:
What if the user is using an expired credit card?
How do you make sure an item doesn’t go out of stock while the user is deliberating the purchase on the checkout screen?
What if you identify this user as fraudulent? Do you ban them from the platform immediately?
Most software products rely on the same core components and have similar patterns that you can pick up over time. Once you build an intuition for these systems, you’ll be able to reason about the relative complexity of features because you understand how it impacts the entire system. Combining this intuition with an understanding of the software development lifecycle is much more important than learning how to write a for loop in JavaScript.
Software Development Lifecycle
“Whenever a user signs up, let’s require them to validate their email before they can use the app.”
This was one of my first tasks on the engineering team at Dharma. How hard could it be? Just send an email to the user after they sign up. A few minutes right? However, what most non-engineers usually don’t realize is that building software products is about much more than writing code.
First, the engineer needs to work with a designer and product manager to consider all the possible scenarios - How do we handle users that are already logged in? Do we force log them out or wait until they log out themselves? Should we expire the email link after a period of time? (We decided to not force log users out since it would be a bad user experience and we didn’t expire the email link for the MVP.)
Next, you need to think about how to store whether a user is verified. Do you add a new database table or add it as a column on an existing table? Should there just be one extra column or multiple columns? What should the column types be - strings, integers, dates? (We created a new table called UserVerificationStatuses that included a userId, a verificationStatus which is true or false, and a token that’s included in the email which our app uses to validate the user.)
Since we decided to add a new database table, we need to run a migration so our database knows about our table and it’s schema (the columns and their data types).
By now, you probably have to stop for lunch or a meeting or a game of ping pong.
Once you’re done with that, you still aren’t writing code. Before that, you need to figure out where the sign up code lives in the codebase. Since this feature is on both the frontend (sign up and login pages) and the backend (API and database), you’ll need to track down where to add your code.
Next, you need to decide how to update your code. Do you want to do it your way or the way that the previous engineer did it? You may think your version is easier to understand but then it makes the code inconsistent which will confuse the next engineer that updates this code.
Finally, you can start actually writing the code. Notice how much work goes into building software that isn’t related to writing code so far - thinking about the user experience, considering what data needs to be stored to the database and how, where does the current code live, then, how should you update it?
Now, you can focus on writing the code for the feature which could take anywhere from a few hours to a couple days. While writing the code, you incrementally test in your local environment which is separate from the app that users see.
Oh shit, you just got a Slack message saying the other feature you launched recently has a bug so you need to go back and fix that which takes half a day.
Once you’ve fixed that bug and you’ve tested all the permutations of this feature, you need to get your code approved by another engineer which could also take a few hours depending on how busy your team is.
During the review, the other engineer blocks you from merging your change because you used tabs instead of spaces for indentation so now you need to go back and update your code and get the engineer to review it again.
Once your code is tab-free, you deploy your code to a test environment that runs on production data (usually called the “staging” environment)
You test the feature again to make sure it’s all working. If anything is off you need to go back to track it down which could take a few hours
After your code is working as expected in the staging environment, you can now deploy to production. Yayyy.
Depending on how your deployment pipeline works, you could wait anywhere from 20 minutes to over an hour.
Even then, you still need to test in production by turning the feature on just for people on your team to make sure everything is working as expected and that you considered all of the main scenarios.
This example may seem contrived but it includes many of the parts of an engineer’s workflow that don’t include writing code. Most of the time in building software is spent planning, testing, and tracking down bugs.
For bigger projects, like re-architecting the onboarding flow, you’ll probably spend a couple days upfront researching potential system designs, getting feedback from other engineers, investigating what code currently exists that you can reuse, and iterating until you come up with a system that meets your goals.
As someone looking to become technical, the idea here is to build empathy for the software development process. Granted, many engineers do scope work to take twice as long as it should so they can show up at 10:30am and leave at 5pm every day to “pown some noobs” in Fortnite. However, once you become technical, you can push back on an engineer’s timeline since you’ve built intuition around how long certain projects should take.
After your team goes through the software development lifecycle to launch a feature, how do you analyze data to ensure the next iteration is closer to your goal?
Interpreting data
Over the last two years, 90% of the data in the world was generated. Additionally, there are now countless tools for easily ingesting, formatting, and visualizing this data (see below)

In an age with nearly infinite data, how do you make sure you’re using the data correctly? To become a data ninja, go through a process using decision trees and hypotheses to know what data to look at and what questions to ask.
Decision Trees
A decision tree helps you logically break down a problem into it’s component parts so you can quickly identify potential levers for improvement. Here’s an example (left to right):
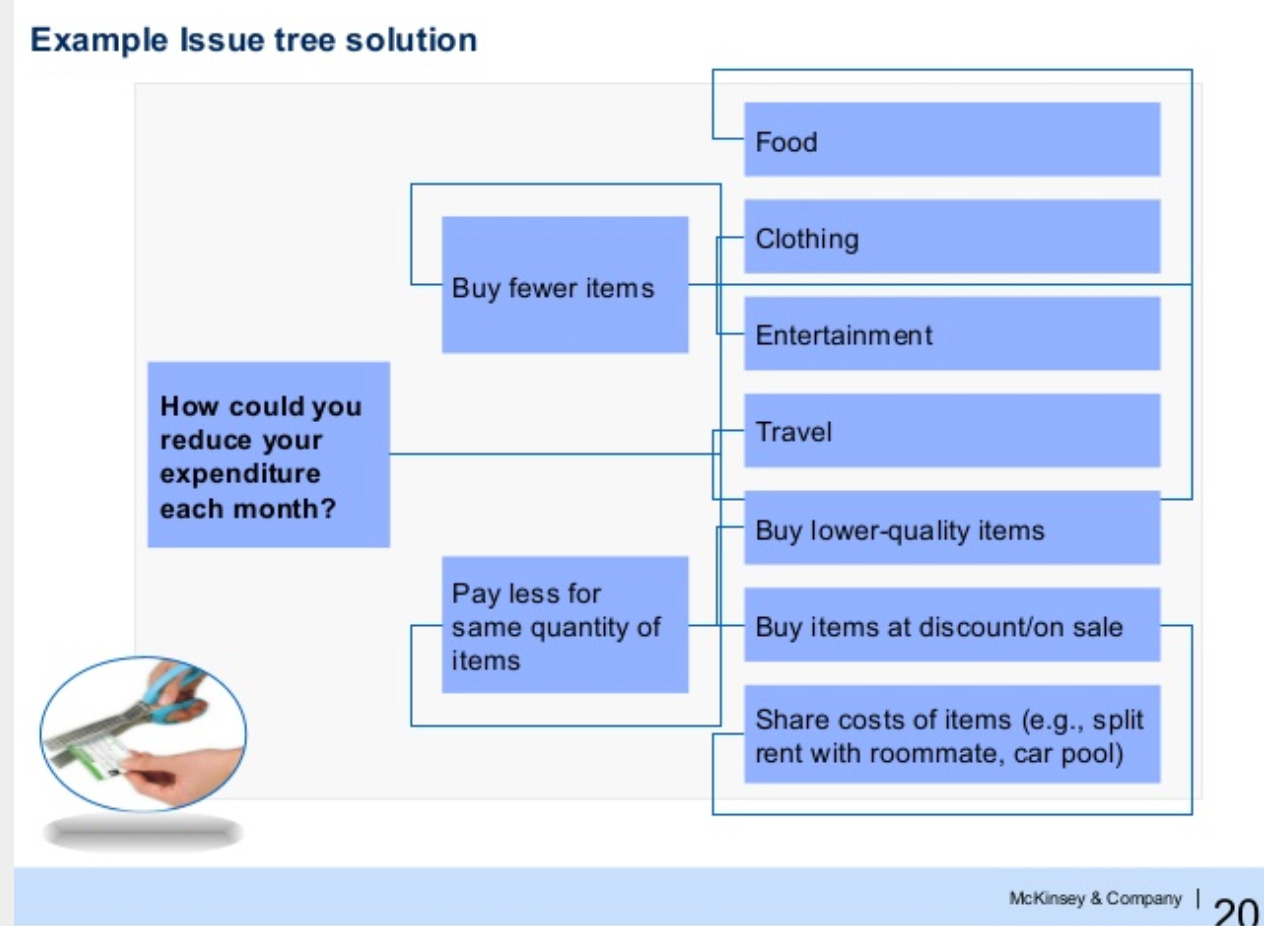
This example takes the problem of reducing monthly expenditures and models it using a principle called MECE (mutually exclusive, collectively exhaustive). In other words, all the branches of the tree should include all possible options (or at least the most important ones) and each option should be independent of the others (e.g., you can do one option without doing the other).
Another example is deciding how to get from Washington D.C. to New York. Logically, a few options are driving, plane, or public transportation. If you want to drive, are you taking your car or renting? If taking a plane, which airline and at what time? If using public transportation, you can choose a bus or train.
You can begin to look at many life decisions through the lense of a decision tree. When building products, you can model all your key metrics with a decision tree. Want to increase your sign up rate? Break it down into each of the component parts:
landing page
click button
redirect to sign up page
add email and password
click sign up.
Now that your sign up flow is modeled in a MECE fashion, you can now seek out data to look at the conversion rates for each step in the funnel and optimize from there. Once you build an intuition for decision trees you’ll be able to use them to get to the core of many problems in a matter of moments.
It’s critical to take time upfront to model your KPI’s with key levers before ever looking at a piece of data.
Hypotheses
The tech industry basically took what you learned in third-grade science class, the scientific method, and rebranded it as the “lean startup methodology”.
Sounds a lot cooler right?
Regardless, hypotheses form the crux of any sound experiment or product development process.
A decision tells you the “what” of a problem (e.g., what is going well or poorly?) and hypotheses help you understand “why”.
For example, once you’ve used a decision tree to identify that most users in your signup flow are dropping out once they reach the sign up page, you can begin to come up with hypotheses as to how to improve the experience. Example hypotheses could include:
What if we added the ability to sign up with your Google or Facebook account?
What if we removed the password field and emailed users after they sign up to create their password?
What if we had them enter their phone number and verify them that way instead?
After coming up with some hypotheses, it’s now obvious what data you need to prove or disprove it. You can use industry data or you could run an experiment internally.
This process of creating a decision tree to identify key levers, developing a hypothesis around a potential solution, running an experiment to gather data, and proving or disproving your hypothesis is a powerful way to make sure you’re getting the most out of your time and data.
Growth Loops
Ah, growth loops. My favorite.
Once you’ve built a product that solves a real user pain point, you need a plan for growing your product sustainably - not by selling a dollar for 95 cents.
Many startups over-rely on paid acquisition (mainly Google/Facebook ads) because it’s an easy way to juice your growth numbers. However, paid acquisition is becoming so saturated that the cost of getting a user to use your service is usually much more than the revenue you receive from them. Therefore, unless you have a way of retaining your users long enough to have positive unit economics, every new user is basically lighting crisp dolla bills on fire. There has to be another way.
Enter: growth loops.
A growth loop is a system where each new user leads to more new users joining your product in a profitable way. How does this happen? The two main drivers of growth loops are word of mouth and SEO (search engine optimization).
If you’ve followed the steps above and built a killer product, new users will be so excited about it that they’ll often tell their friends about it over bottomless mimosas on the weekend or share on social media.
Instead of ads, humans spread the gospel of your product for free.
This is why it’s so important to obsess over customers. Not only will they use your product, they’ll also tell their friends about it. Because word of mouth is such a cost-efficient way of acquiring users, companies have developed creative strategies to drive virality:
By default, emails from people using the service Superhuman, include a signup link in the footer
Dropbox grew 3900% in 15 months by giving users free storage space for referring friends
Upstart credit card companies offer sleek cards and more points when users refer others
On the other hand, SEO takes quite a bit of time to get the flywheel going and usually works best for companies with user-generated content like posts or photos (e.g., Quora, Pinterest, Zillow).
Below, we can see an example of how Pintereset leveraged SEO as the foundation for their growth loop:

As you can see, user-generated content was at the core of Pinterest’s growth loop.:
Personalized content convinced users to sign up
Then a user would save or add content, which improved the personalization algorithms
Afterwards, Pinterest would create custom landing pages with content on different topics (e.g., women’s fashion, home decor, cooking)
The landing page would rank highly in Google searches which would then drive more traffic and start the loop again
By understanding growth loops, you’re able to come up with creative strategies for your company to achieve sustainable growth.
Conclusion
If you want to be technical, don’t focus on learning to code. Instead, develop customer obsession, come up with an iterative product development process, understand the role of key software components, develop empathy for the software development lifecycle, interpret data by asking good questions, and identify some core growth loops for your product.
Engineers will thank you for it :)
If you enjoyed this post and want to receive more like it right in your inbox, sign up below:
And feel free to share with anyone that may find it valuable:
Thanks for your support and don’t hesitate to reach out with any questions or feedback!